GRACE TECHNICAL REPORTS
Beanbag: Operation-based Synchronization with
Intra-relations
Yingfei Xiong, Zhenjiang Hu, Haiyan Zhao, Masato
Takeichi, Song Hui, Hong Mei
GRACE-TR-2008–04 December 2008
CENTER FOR GLOBAL RESEARCH IN
ADVANCED SOFTWARE SCIENCE AND ENGINEERING NATIONAL INSTITUTE OF INFORMATICS
テクニカル・レポートは、国内外の論文誌、Proceedings等への投稿原稿、マニュア ル、資料、研究の中間報告です。著作権は、全て著者に属します。ただし、同一ある いは類似の論文が外部の論文誌等で発行される場合はホームページへの掲載等を中止 することがあります。その場合、著作権者が学会等に変更される場合もあります。
Beanbag: Operation-based Synchronization with
Intra-relations
Yingfei Xiong1, Haiyan Zhao2, Zhenjiang Hu1,3, Masato Takeichi1, Song Hui2, Hong Mei2
1
Department of Mathematical Informatics University of Tokyo, Tokyo, Japan
{Yingfei Xiong,takeichi}@mist.i.u-tokyo.ac.jp
2
Key Laboratory of High Confidence Software Technologies (Peking University)
Ministry of Education, Beijing, China
{zhhy,songhui06,meih}@sei.pku.edu.cn
3
GRACE Center
National Institute of Informatics, Tokyo, Japan [email protected]
December 11, 2008
Abstract
Modern development environment often involves data with complex rela-tionships. When users update some part of the data, we need to synchronize the update to make all data consistent.
Bidirectional transformation supports synchronization by propagating up-dates between two replicas, from one replica to the other or vice versa. How-ever, replicas are often constrained with intra-relations, and we may have to propagate updates within one replica. Such kind of propagation is not well supported by current bidirectional transformation.
1
Introduction
Modern development environment often involves data with complex relationships. For example, different diagrams in a UML model are related, and the UML model and its generated code are related. When users update some part of the data, we need to transform and propagate the update to other part to make all data consistent.
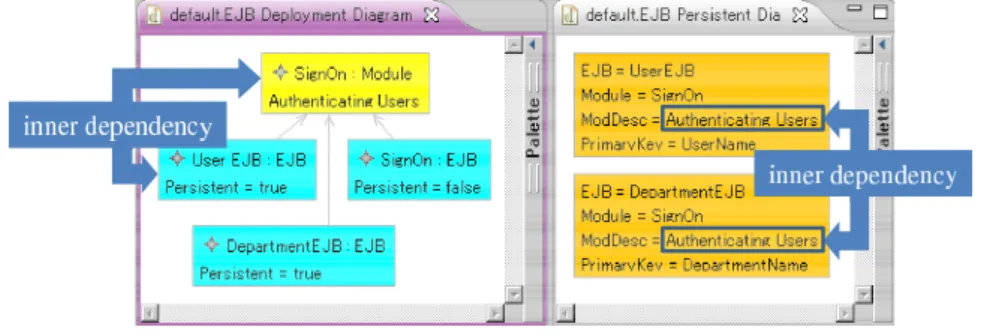
Figure 1: An EJB Modeling Tool
Figure 1 gives a concrete example, which depicts a simple Enterprise Jav-aBeans (EJBs) modeling tool. The tool provides two types of editable diagrams: the deployment diagram and the persistent diagram. The deployment view shows how EJBs are organized into modules, while the persistent diagram shows a list
of persistent EJBs (entity beans). In Figure 1 there are three EJBs: SignOnEJB,
UserEJB, andDepartmentEJB, all of which belong to a moduleSignOn. The
persistent attributes ofUserEJBandDepartmentEJBaretrue, indicating they
are entity beans and are listed in the persistent diagram. In many places the two diagrams are related, such as the EJB names shared in the two diagrams. When users update an EJB name in one diagram, the corresponding name in the other diagram also need to be updated to make the two diagrams consistent. The pro-cess of propagating updates between heterogeneous data is called heterogeneous
synchronization and the software components to perform such synchronization are
called synchronizers [ACar].
Bidirectional transformation [Ste07, FGM+07] provides support for
heteroge-neous synchronization. A bidirectional transformation contains a consistency
re-lationR ∈ A×B between two heterogeneous data formats, a forward function
f : A×B → B and a backward functiong : A×B → A [Ste07]. Given two
inconsistent replicas of data inAandB, bidirectional transformation changes one
replica according to the other, or vice versa, to make them consistency. Typical bidirectional transformation languages include QVT Relations [Obj08] and TGGs [KW07].
Bidirectional transformation works well when the two replicas can be freely modified. However, in the real world many application data may also be con-strained with intra-relations and update of one location may require updates of other location. Two examples of intra-relations are indicated with thick arrows in
Figure 1. In the deployment diagram theSignOnmodule and its EJBs are
all EJBs, or at least, remove the invalid associations. The intra-relations in the per-sistent diagram concerns two related module description. When one is modified, we need to modify the other to make sure they are consistent. As bidirectional transformation only propagates updates between the two replicas, it cannot well handle data with intra-relations.
Intra-relations impose many new challenges and call for some non-trivial im-provements on bidirectional transformation. We summarize the challenges as fol-lows.
• First and foremost, intra-relations call for a new synchronization interface.
Consider the intra relation in the persistent diagram, the system needs to know which part of the data is modified to correctly overwrite the unmodi-fied data with the modiunmodi-fied data, and this information is not available in the state of data. Furthermore, the synchronization directions are not limited to forward and backward, as the propagation along intra-relations can be of many directions once.
• Second, intra-relations often have mutual effects with inter-relations.
Con-sider the intra-relation in the deployment diagram. If an EJB is deleted due to the deletion of a module, we should also delete the corresponding entity bean in the persistent diagram. The intra-relation in the persistent diagram is more interesting. From the persistent diagram alone, the two module de-scriptions are not related. The two dede-scriptions are related because they cor-respond to the same module element on the deployment diagram. Because of such mutual effects, we need an unified way to connect intra-relations and inter-relations together.
• Third, the complexity of intra-relations usually leads multiple options in
syn-chronization. For example, when a module is deleted in the deployment dia-gram we have options to remove only the associations or to also remove the child EJBs. We need provide means for users to specify these options and therefore precisely control the synchronization behavior.
In this paper, we study the language support of synchronization with intra-relations over dictionary-based data. We focus on dictionaries to make our lan-guage compact. Dictionaries can be used to represent many different data
struc-tures as studied by Pierce et al. [PSG03]1, and we will show how to encode object
model like the EJB modeling tool in dictionaries.
In our study we adopt operation-based synchronization. Traditional bidirec-tional transformation can be classified as state-based synchronization [PSG03], as the current state of data are taken as input as input. Unlike the state-based way, the operation-based synchronization takes update operations applied on data and pro-duces new update operations to make all data consistent. In this way we address the first challenge: the modified parts can be deduced from updates and propagation is not restricted to a specific direction.
1
The result of our study is called Beanbag, a new language for operation-based synchronization with intra-relations. The name of Beanbag is contrived from a traditional Asia game that keeps several beanbags consistent. Our contributions can be summarized as follows.
• We propose the Beanbag language for users to describe the consistency
relation over data. The Beanbag language treats intra-relations and inter-relations in a unified way, and users can freely compose the inter-relations using logical operators like conjunction and disjunction. In addition, we provide finer control over synchronization behavior, while keeping Beanbag program easy to write.
• We give a clear execution semantics to convert the consistency relations
de-scribed in Beanbag to a synchronizer. The implemented synchronizer takes user updates as input, and produces new updates to make all data consis-tent. The synchronization satisfies the stability, preservation and consistency
properties [XLH+07], guaranteeing a correct synchronization behavior.
• We have implemented Beanbag in Java [Bea], evaluated its performance by
experiments, and evaluated its practicability by several case studies. The experiments show that Beanbag is much faster than an incremental imple-mentation of QVT relations[ikv], and the case studies show that Beanbag works well in practical applications. We also discovered an extra benefit of Beanbag during the development of applications: we can get rid of the key attributes used in many bidirectional transformation approaches [Obj08,
BFP+08] due to the tight integration between operation-based synchronizers
and applications.
The rest of the paper is organized as follows. Section 2 gives an overview of Beanbag while Section 3 presents detailed semantics. Section 4 describes our implementation and the experiments we have conducted. Section 5 gives two case studies that we have conducted and explains how we get rid of the key attribute. Finally, Section 6 discusses related work and Section 7 concludes the paper.
2
Overview
To illustrate the features of Beanbag and give a concrete impression of what our system can do, let us consider how to develop a synchronization tool for the EJB example in Figure 1. To develop the tool, the only thing we need to do is to declare the consistency relations over diagrams in the Beanbag language. The execution semantics of Beanbag could turn the program into a synchronizer and synchronize the diagrams through updates. The full Beanbag program used in this section can be found in Appendix A and Appendix B.
module objects and EJB objects in the deployment view, and entity bean objects in the persistent view. By assigning each object with a unique key, we can represent the EJB objects in Figure 1 by the following dictionary (a mapping from keys to objects):
{17→{"Name"7→"SignOnEJB", "Persistent"7→false,
"Module"7→4}, 27→{"Name"7→"UserEJB",
"Persistent"7→true,
"Module"7→4},
37→{"Name"7→"DepartmentEJB", "Persistent"7→true,
"Module"7→4}}
It has three EJB objects with keys 1, 2, and 3. Each attribute of an object ("Name", "Persistent", or "Module") points to either a primitive value or a key (4 in this example) to another object. It is worth noting that dictionary, though being simple, plays an important role in our language; it not only enables concise description of objects (and their relations) , but also provides a direct means to access and update each object.
Similarly, we can represent modules in Figure 1 as follows (we omit the defi-nition of the entity beans in the persistent view).
{47→{"Name"7→"SignOn",
"Description"7→"This module is ..."}
After defining the data structure by dictionaries, we step to declare the consis-tency relation using our synchronization language Beanbag. We want to declare two types of relations: the inter-relations between diagrams and the intra-relations within one diagram. In Beanbag these two types are captured in a unified way. First, we describe the top relation among the EJBs, the modules, and the entity beans.
1 main(ejbs,modules,entitybeans) {
2 containmentRefshattr="Module"i(ejbs,modules);
3 for[ejb,entitybean]inhejbs,entitybeansi{
4 persistent(ejb,entitybean,modules) |
5 nonPersistent(ejb,entitybean) |
6 {ejb=null;entitybean=null}
7 }
8 }
It says that (1) EJBs have a containment relation with modules (line 2) in the sense that if a module is deleted then all EJBs belonging to the module should be deleted,
(2) for each pair of (ejb, entitybean) in (ejbs, entitybeans)
respec-tively, they have either thepersistentrelation (line 4) or thenonPersistent
relation (line 5), or both of them are deleted at the same time (line 6). The relation
containmentRefsis provided by the standard library and we will see its
defini-tion in Secdefini-tion 3.3. Thepersistentrelation and nonPersistentrelation are
relations to be refined.
the parameters ofmain(ejb,modulesandentitybeans) are all treated equally.
We do not have to specifyejbandmodulesare in the same diagram nor impose
any propagation direction among them. Second, the intra-relations and the inter-relations are treated equally. Line 2 captures the intra-relation on the deployment diagram and the rest lines capture the inter-relations between the two diagrams. Both of them are described using the same set of constructs. The intra-relation
on the persistent diagram is implicitly captured in thepersistentrelation. Let
continue to declare thepersistentrelation.
9 persistent(ejb,entitybean,modules){
10 var moduleRef,moduleName,module;
11 ejb."Persistent"=true;
12 entitybean."EJBName"=ejb."Name";
13 entitybean."ModuleName"=moduleName;
14 moduleRef=ejb."Module";
15 findByhattr="Name"i(modules,moduleName,moduleRef);
16 module."Description"=entitybean."ModuleDescription";
17 module=!modules.moduleRef;
18 }
It says that the EJB should be persistent (line 11) with the same name as that of the entity bean (line 12), while the entity bean has an module name (line 13), and if we find out the module by the name from all modules (line 13), the result
should just be the module referred by the EJB (line 14). The findyByis also
a standard library relation described in Section 3.3. The entity bean also has a module description, which is equal to the description of the module referred by the EJB (line 16-17). The “!” in line 17 is used to tune the synchronization behavior and will be introduced in Section 3.3. Note here we related the module description in the entity bean and that in the module. If several entity beans shares the same module name, the module descriptions in these entity bean will be indirectly related and result in the intra-relation in the persistence view.
ThenonPersistentrelation is similarly defined as follows. 18 nonPersistent(ejb,entitybean) {
19 ejb."Persistent"=false;
20 entitybean=null;
21 }
As seen above, our synchronization program is of high modularity in the sense that small synchronization relations can be glued to form a big one. Beanbag is simple to use; the basic synchronization statements in Beanbag are the equality “=” to describe primitive relation, and synchronization statements are combined
together with “;” (called conjunction) and “|” ( called disjunction), and the for
statement to apply a relation inside dictionaries. The details about the language are given in Section 3.3.
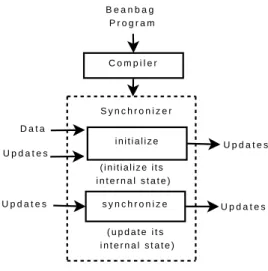
That is all we have to do. After the synchronization relations are given, our system can automatically produce a synchronizer for keeping the two views con-sistent. To be concrete, let us see how the synchronizer interacts with users in action.
synchronization, we need to initialize the synchronizer so that it knows what data
will be synchronized. Theinitializeprocedure is also useful in the execution
of disjunction and the for statement, as will be seen in Section 3.3. We invoke the
initializeprocedure with three initial values and three initial updates for the
three parameters ofmain.
Initial values: [{}, {}, {}] Initial updates: [void, void, void]
The initial values are all empty dictionaries, indicating no objects at the begin-ning. The initial updates are used to control the behavior of initialization and will
be explained in details in Section 3. Here we just passvoid, indicating no initial
up-date. After invocation, theinitializeprocedure will return the following result
to indicate that we do not have to modify the initial values.
Output updates: [void, void, void]
After initialization, we use the synchronizeprocedure to synchronize user
updates. Suppose users have added a new entity object. This update can be de-scribed as follows. The dictionary structure indicates the location of updates and “!” indicates the value at the location is replaced by the value following “!”.
Input: [void,
void,
{17→{"EJBName"7→!"UserEJB", "ModuleName"7→!"SignOn"}}]
To synchronize the updates, we invoke the synchronize procedure of the
synchronizer with the updates as input, and the synchronizer will produce the fol-lowing output updates. The output updates are expected to be applied on data to make the data consistent. In the updates an EJB object and a module object are created and their attributes are properly set. Note the input update is also kept in the output.
Output: [{27→{"Name"7→!"UserEJB", "Persistent"7→!true, "Module"7→!3}}, {37→{"Name"7→!"SignOn"}}, {17→{"EJBName"7→!"UserEJB",
"ModuleName"7→!"SignOn"}}]
Suppose users have modified the name of the EJB to"User". The input and
output of the synchronization are as follows. The EJB name of the corresponding entity bean is changed.
Input: [{27→{"Name"7→!"User"},void,void}] Output: [{27→{"Name"7→!"User"},void,
{17→{"EJBName"7→!"User"}}]
For another example, suppose users want to delete the module. The input and output of the synchronization are as follows. The EJB belonging to the module is deleted, and so does the corresponding entity bean.
Input: [void,{37→!null},void]
C o m p i l e r B e a n b a g P r o g r a m
S y n c h r o n i z e r
i n i t i a l i z e D a t a
U p d a t e s U p d a t e s
s y n c h r o n i z e
U p d a t e s U p d a t e s ( i n i t i a l i z e i t s
i n t e r n a l s t a t e )
( u p d a t e i t s i n t e r n a l s t a t e )
Figure 2: How Beanbag works
As discussed in Section 1, along intra-relations usually we have multiple op-tions in synchronization. When users delete the module, we can also only remove the associations to achieve consistency. This can be done by replacing the state-ment in line 2 with the following statestate-ment.
nullableRefshattr="Module"i(ejbs, modules);
That is, we use the nullableRefsrelation to replace the containmentRefs
relation, andnullableRefsis also a relation defined in the standard library. Now
if we repeat the above steps again, the synchronizer will produce the following output which remove only the association.
Input: [void,{37→!null},void]
Output: [{27→{module7→!null}},{37→!null},void]
Another interesting example of multiple options in synchronization is that an entity bean is deleted, we can either remove the corresponding EJB or just set its
persistent attribute to false. The current Beanbag program will set the
persis-tent attribute tofalse, but we can change this behavior by simply swapping the
two statements in line 5 and line 6. The new program will give higher priority to
deletion over thenonPersistentrelation, and will delete the corresponding EJB
when an entity bean is deleted.
3
The Beanbag Language
We have seen how Beanbag works in Section 2, and this is summarized in Fig-ure 2. A Beanbag program is compiled into a synchronizer which consists of two
procedures. Theinitializeprocedure initializes the synchronizer. It takes
ini-tial data and updates as input and produces new updates to make the input data
consistent. Thesynchronizeprocedure synchronizes data. It takes user updates
and produces new updates to make data consistent.
prop-value ::=primitive|dictionary
primitive ::=null|STRING|NUMBER|BOOLEAN
dictionary ::={entries}
entries ::=entry|entry,entries entry ::=primitive−>value
Figure 3: Definition of data
erties to constrain the behavior of synchronizers. The three properties are adapted
from our previous work [XLH+07] on state-based synchronization. The first
prop-erty, stability, requires that when users modify no data item, the synchronizer should modify no data item, either. The second property, preservation, requires the output updates should contain the input updates. In other words, when users
modify a data item, for example, to2, the synchronizer should not modify the data
item to any other value different from2. The third property, consistency, requires
the synchronizer to produce correct updates to make all data consistent. After we apply updates produced by a synchronizer to data, we can know the data are consis-tent. This property is formerly defined as propagation in our previous publication
[XLH+07].
Thesynchronizeprocedure satisfies all the three properties. Theinitialize
procedure satisfies preservation and consistency. It does not satisfy stability be-cause the input data may not be consistent.
3.1 Data
Beanbag uses a small but general set of data types to represent data. In this way our language remains compact, but many other data types can also be mapped to our data types and synchronized by our synchronizer. Figure 3 shows the definition
of data in BNF. The italic symbols are non-terminals and theSans Serif
sym-bols are terminals. STRING,NUMBERandBOOLEANare lexical tokens of common
meanings.
There are two types of data. The ruleprimitivegenerates unstructured
prim-itive values, including numbers, strings, booleans and a null value. The rule
dictionarygenerates structured dictionaries, which map primitive values (keys)
to other values. A key-value pair is called an entry. If a key is mapped tonull, it
means that the key does not exist in the dictionary. That is,{"a"7→null}and{}
are both empty dictionaries. We writed.kfor the value to which the dictionaryd
maps the keykif no confusion will be caused.
Many other data structures can be mapped to this dictionary-based data types. We have seen how to map object models to the data types in Section 2. For more examples, a set can be mapped to a dictionary by assign each value a unique key or using the in-memory address of each value as its key. A sequence can be mapped
to a dictionary by simulating the implementation of a linked list, that is, ["a",
"b", "c"]can be represented as{"value"7→"a","next"7→{"value"7→"b",
update ::=void|prim update|dic update
prim update ::= !primitive dic update ::={update entries}
update entries::=update entry|update entry,update entries update entry ::=primitive−>update
Figure 4: Definition of updates Table 1: The rules of detecting conflicts
void prim update2 dic update2
void false false false
prim update1 false result1 true
dic update1 false true result2
where result1≡(prim update16=prim update2)
result2≡(∃k:dic update1.kand dic update2.kconflict)
3.2 Updates
We capture users’ updates by locations of updates and results of updates. The syntax of the language for describing updates is shown in Figure 4. The
non-terminalprimitivehas been defined in Figure 3.
The syntax is similar to that of values. An update can be either prim update
– an update on primitive values, dic update – an update on dictionaries, or void
– an update indicating that nothing has been changed by users. An update on primitive values is just to replace old value with a new value. For example, if
we apply !2 to a value 1, the value 1 will change to 2. An update on
dictio-naries maps keys to updates, where the updates are expected to be applied on the values mapped by the same keys. If a key does not exist in a dic update,
we consider the key is mapped to void. For example, if we apply an update
{17→!null, 27→!"a", 37→{"x"7→!"y"}} to a dictionary{17→"n", 27→"m",
47→"z"}, we will get{27→"a",37→{"x"7→"y"},47→"z"}.
If two updates change the same location to different values, we say that the two
updates conflict. For example,{17→!"a"}and{17→!"b"}conflict but{17→!"a"}
and{27→!"b"}do not. The complete rules for detecting conflicts are summarized in Table 1. The cells in the table show whether the update from the left conflicts
with the update from the top. Here we write dic update.kfor the update to which
dic update mapsk.
In many cases, users perform a sequence of updates instead of a single one, which requires us to merge a sequence of updates into a single update. Table 2 shows the rules for merging two updates. The left of the table shows the up-date applied earlier, the top of the table shows the upup-date applied later, and the
cells show the merged results. For example, merging{17→"a", 27→"b"} with
{17→"c", 37→"d"} results in {17→"c", 27→"b", 37→"d"}. Non-conflicting
updates are commutative under merging, e.g., merging{17→"a"}with{27→"b"}
Table 2: The rules of merging updates
void prim update2 dic update2 void void prim update2 dic update2
prim update1 prim update1 prim update2 dic update2
dic update1 dic update1 prim update2 dic update3
where∀k:dic update
3.k≡(dic update1.kmerges dic update2.k) 3.3 The Beanbag Language
Every Beanbag program has two types of semantics. First, the relation semantics defines the consistency relation over data. Second, the execution semantics defines how to propagate updates to satisfy the relations. In many cases, users only need to know the relation semantics to understand a Beanbag program. However, if they want to know more about how updates are synchronized, or want to write a Bean-bag program to control the synchronization behavior, they need also to understand the execution semantics. In this section we introduce the two types of semantics.
3.3.1 The Relation Semantics
Table 3 summarizes the relation semantics of the core language constructs by ex-amples. The core language constructs are divided into five groups. Named relations
allow us to organize programs modularly, andmaindeclares the entry relation of a
program. Expressions are the primitive relations we can use in Beanbag programs, and most of their relation semantics is as same as what we can expect from their
syntax. Conjunction, disjunction and theforstatement allow us to compose small
relations using common logical operators. Conjunction represents the logical
op-erator “and”. Disjunction represents the logical opop-erator “or”. Theforstatement
applies a relation to each sequence of entries in a sequence of dictionaries. We can require the sequence of entries to have the same key (line 13) or allow them to be freely matched (line 14). In addition, we can choose to capture the key component (line 14) or not (line 13).
Some language constructs have different syntax but have the same relation
se-mantics. One example is a=banda==b. Another example is!d.k=v, d.!k=v
and!d.!k=v. This is because for the same consistency relation, we may have more than one way to synchronize the updates. The different language constructs represent different ways of synchronization, which allows us to finely control the synchronization behavior. The details of the difference will be introduced in the next section.
3.3.2 The Execution Semantics
When compiled, a beanbag program is converted into a synchronizer, and this is achieved by converting each language construct in the program into a synchro-nizer and combining them together. The expressions are turned into primitive
Table 3: The relation semantics of the core language constructs
Named relations
0 gethkey="age"i(d,k)
{d.key=k}
declaring a named relationget, wherekey
is a generic parameter with a default value
"age".
1 main(d,k){get(d,k)} defining the entry relation of the program. Expressions
2 a=b the two variables,aandb, are equal.
3 a=1 the variableais equal to the constant 1.
4 d."k"=v vis equal to the value to which the dictionary dmaps the constant"k".
5 !d.k=v vis equal to the value to which the dictionary dmaps the variablek.
6 d.!k=v vis equal to the value to which the dictionary dmaps the variablek.
7 !d.!k=v vis equal to the value to which the dictionary dmaps the variablek.
8 a==b the two variables,aandb, are equal.
9 a6=b the two variables,aandb, are not equal. 10 gethkey="name"i(a, b); calling a named relationget
Conjunction
11 {var c;
c=a."name";b."name"=c;}
exists c, where c=a."name" and
b."name"=cboth hold. Disjunction
12 {a=true|a=null} eithera=trueora=null
For statement
13 for[a,b]in[dictA,dictB]
{a=b} for any keyk, we havedictA.k=dictB.k.
14
for[hk1,v1i,hk2,v2i] in hd1,d2i
{rel(k1,v1,k2,v2);}
exits a bijective relation R over keys, where ∀ hk1, k2i ∈ R, the inner relation
rel(k1, d1.k1, k2, d2.k2)holds.
composite synchronizers where small synchronizers are glued together to form a bigger synchronizer. Every synchronizer, either primitive or composite, has the
initializeprocedure and thesynchronizeprocedure. In this section we de-fine the execution semantics of Beanbag by describing how these language con-structs are turned into synchronizers and how the two procedures of these synchro-nizers behave.
Expressions Expressions are converted to primitive synchronizers in compila-tion. In synchronization, these synchronizers try to produce updates that change minimal parts on data and also satisfy the three properties.
As an example, let us consider a simple synchronizer,a=b, shown in line 2 of
Table 3. This synchronizer synchronizes variablesaandbby keeping them equal.
The variablesaandbmust be declared as parameters of a named synchronizer or
declared in other outer constructs. In thesynchronizeprocedure, the
example, if users updatea to 1 and do not modify b, the procedure will merge
the update!1andvoid, and returns the merged result!1on bothaandb. If the
updates on the two variables conflict, the procedure will fail and report an error. In this way we can propagate the update on either variable to the other, i.e., deducing a propagation direction from updates. In addition, the stability, preservation and consistency properties are all satisfied.
Theinitializeprocedure ofa=bis a bit more complex. Because we do not require the input values to be consistent, we may face multiple options in synchro-nization. When the input values are not equal, we will have two choices: using the
value ofato overwritebor vice versa. We allow users to customize this behavior
through the input updates. Because of the preservation property, the updated part cannot be modified. Then users can use the input updates to mark some unmodifi-able part and force the synchronizer to modify other part. When the input updates
on the two variables are bothvoid, the synchronizer will choose the natural order
of assignment, i.e., using the variable at the right of “=” to overwrite the variable
at the left. In the case ofa=b,awill be overwritten byb. This choice also applies
to other expressions connected by “=”, and users can make use of this feature to
further control the behavior of synchronization. Theinitializeprocedure of
a=bproceeds as follows. It first merges the updates onaandb, and applies the
merged update ona. Then it updatesbto the newaand produces the result.
One interesting part is the expressions between line 5 and line 7. These
expres-sions involves three variables,d,kandv, and tries to keepvequal to the value in
the location to whichdmapsk. Because we have three variables, whenvchanges,
we can propagate the update to eitherdork, or both. We use “!” to indicate the
variable to which the update is going to be propagated. The expression!d.k=v
propagates the update onvtod, that is, it useskas a constant value and proceeds
liked."k"=v. The expressiond.!k=vpropagates the update onvtok, that is, it
usesdas a constant value and tries to find a key whose corresponding value ind
equals the updatedv. When such a key cannot be found, it reports a failure. The
expression!d.!k=vpropagates the update on vto bothdandk. Its behavior is
similar tod.!k=v, but when a proper key cannot be found, it inserts a new key to
the dictionary. In this way we can precisely control what to update and what not to.
For example, suppose the current values ond,kandvare[{1="a", 2="b"},
1,"a"], and the input updates ond,kandvare[void,void,"c"]. Thesynchronize
procedure of!d.k=v will return an update {17→"c"} on d, the synchronize
procedure ofd.!k=vwill fail, and thesynchronizeprocedure of!d.!k=vwill
return an update{37→"c"}ondand{!3}onk. The new key3is generated by a
unique key generator to make sure it is different from all existing keys.
Conjunction Line 11 of Table 3 shows conjunction of synchronizers, which tries to establish the consistency relations of all inner synchronizers. In addition,
users can also define inner variables. In thesynchronizeprocedure, the input
updates on inner variables are considered asvoid. In theinitializeprocedure,
the input updates on inner variables are considered asvoidand the input data on
inner variables are considered asnull.
Thesynchronizeprocedure of conjunction works as follows: whenever the
update on a variable changes, thesynchronizeprocedures of the inner
synchro-nizers declared on the variable will be invoked. When no inner synchronizer can be invoked, the procedure returns. When there are more than one inner synchronizers that can be invoked, the one appearing earliest in the declaration will be invoked first. As an example, the following table shows an invocation of the synchronizer in line 11.
input updates:
a b c
void {"name"7→!"x"} void
bchanges, and we invokeb."name"=c:
void {"name"7→!"x"} !"x" cchanges, and we invokea."name"=c:
{"name"7→!"x"} {"name"7→!"x"} !"x"
Next let us consider theinitialize procedure. The easiest way to
imple-ment the procedure is to adopt the similar method of synchronize, invoking
theinitializeprocedure of inner synchronizers when the values or updates on the related variables need to be synchronized. However, this method may cause unnecessary failures. Consider the synchronizer in line 11. Suppose the input
values onaandbare[{"name"7→"x"}, {}], and the input updates are[void,
{"name"7→!"y"}]. The expected output updates should be[{"name"7→!"y"},
{"name"7→!"y"}] because updates have higher priority than values. However,
when we invoke theinitializeprocedure ofc=a."name", we will get an
up-date!"x"onc, and when we invokeb."name"=c, the procedure will fail because
the updates oncandbconflict.
To solve this problem, we distinguish updates on variables into two levels. The high level is the updates propagated from input updates or the input updates
themselves (such as{"name"7→!"y"}onb). The low level includes the updates
propagated from values (such as!"x"onc) plus the updates in the high level. The
updates in the high level can overwrite those in the low level. For each variable, we store one update for the high level and one update for the low level. After we
distinguish the updates into two levels, the update{"name"7→!"y"}will be on a
higher level than!"x"and will overwrite!"x"without failure.
However, if we design our synchronizers to directly support this kind of two-level synchronization, the semantics of synchronizers would be too complex for both users and language implementers. To keep the language simple, here we propose a novel technique to simulate two-level synchronization using one-level
inner synchronizer, we invoke the procedure twice to give different priorities to the two levels. In the first invoke, we use updates on the low level and store the result on the low level. In the second invoke, we first apply updates on the low level to the values, and pass the new values and updates on the high level to the procedure. The result is stored in the high level, and is also merged into the low level as a later update.
To see how this work, let us consider the previous example again. The initial
values and updates onaandcare shown below.
values low level high level
a {"name"7→!"x"} void void
c null void void
After the first invocation of c=a."name", the values and updates will
be-come:
a {"name"7→!"x"} {"name"7→!"x"} void
c null !"x" void
The second invocation will change no values nor updates because the input
values are consistent and the high level updates are void. Then we proceed to
invokeb."name"=c. Before invocation, the value and updates onbare:
b {"name"7→!"x"} {"name"7→!"y"} {"name"7→!"y"}
The first invocation will fail because the updates on the low level conflict.
How-ever, in the second invocation, an update!"y"will be propagated tocbecause the
high level update oncisvoid. This update will further be merged into the low level
and result is shown below.
c null !"y" !"y"
b {"name"7→!"x"} {"name"7→!"y"} {"name"7→!"y"}
Thenc=a."name"will be invoked again to further propagate the update toa. In this way we simulate multi-level by invoking one-level synchronizers multiple times.
Besides the basic expressions between line 2 and line 10, Beanbag provides more types of expressions as syntax sugars. These expressions are translated into the conjunction of basic expressions at the compiling time. For example, an
ex-pressionb."name"=a."name"will be translated to the code in line 11 of Table 3,
and an expression a."k"==b."k"will be translated to {var c,d; c=a."k";
d=b."k"; c==d;}.
Disjunction Line 12 of Table 3 shows disjunction of synchronizers. Disjunc-tion will try to establish one of the consistency relaDisjunc-tions of the inner synchronizers. The initializeprocedure of disjunction will invoke the initialize proce-dure of inner synchronizers in the order that they are declared, and will return the result of the first succeeded procedure as the result of the whole disjunction. Thesynchronizeprocedure of disjunction will first find the last succeeded inner
synchronizer, and invoke itssynchronizeprocedure. If the invocation fails, the
For example, the following code shows a synchronizer that ensures an object
reference to be valid. TheobjRefreference should either exist in theobjs
dic-tionary or be equal tonull.
nullableRef(objRef, objs){ objs.!objRef6=null | objRef=null
}
For another example, in MOF [OMG02] there is a special reference called
containment reference, which indicates one object is contained in another object
with respect to the reference. When the referenced object is deleted, we should also delete the contained object. This kind of reference can be simulated using the following synchronizer.
containmentRefhattri(srcObj, tgtDict) {
{ var ref; ref=srcObj.attr; tgtDict.!ref6=null; }
| srcObj=null }
For Statement The language constructs we have seen so far are used to
syn-chronize static data structures. Theforstatement is used to dynamically establish
consistency relations over entries in different dictionaries. Line 13 of Table 3 shows
aforstatement. This statement has the same behavior asdictA=dictBover
dic-tionaries. Thefor statement first matches the entries in the two dictionaries by
key, and then applies the inner synchronizera=bto the value parts of every two
matched entries.
In thesynchronizeprocedure offor, the system creates a new instance of
the inner synchronizer and invokes itsinitializeprocedure for newly inserted
pairs, and calls the synchronize procedure of the existing inner synchronizer
for modified pairs. In theinitialize procedure offor, the system creates a
new instance of the inner synchronizer and invokes itsinitializeprocedure for
every two entries.
One use of theforstatement is to filter some entries in a dictionary of objects.
For example, the following synchronizer ensures thatpersistentObjscontains
and only contains the objects whosepersistentattribute istrueinobjs.
filter(objs, persistentObjs) {
for[obj, pobj] in [objs, persistentObjs] {
{obj."persistent"=true;pobj=obj;} | {obj."persistent"=false;pobj=null;} | {obj=null;pobj=null;}
} }
Because we consider a key mapped tonullis a key that does not exist in a
dictio-nary, the synchronizerpobj=nullcan ensure nopobjexist inpersistentObjs.
Note the last synchronizer {obj=null;pobj=null;} is always needed if we
want to handle deletions inobjs.
entity bean and synchronize them. We cannot match the objects by key because the objects are created independently and there is no corresponding relationship between their keys. To support this kind of synchronization, we provide another
matching mode in theforstatement: matching by the inner synchronizer. Two
entries in the two dictionaries are matched if they are successfully synchronized
by the initializeprocedure of the inner synchronizer. Once two entries are
matched, theforstatement will remember their trace relationship. If any of the
two entries are updated, the synchronizeprocedure of the inner synchronizer
will be invoked to synchronize them. We use angle brackets around dictionary variables instead of square brackets to indicate matching by the inner synchroniza-tion.
So far we only useforto synchronize two dictionaries. Theforstatement can
also be applied to more than two dictionaries or just one dictionary. In the latter case, it just applies the inner synchronizer to all entries in the dictionary.
Sometimes we also want to use the key part of an entry in synchronization, and
it can be done by writing hkeyVar, valueVari instead of a single variable in
the binding declaration. Because we do not want users to change the key, the vari-able bound to key will always have a prim update to prevent further modification. Line 14 in Table 3 shows an example of that. An important use of key binding is to obtain the trace between two dictionaries. When entries in two dictionaries are matched by an inner synchronizer, we may want to know which two entries are matched. The following synchronizer shows how to do that.
for[hk1, v1i,hk2, v2i,trace] in hDictA,DictB,traceDicti
{trace."left"=k1; trace."right"=k2; v1=v2;}
The synchronizer uses the idea of TGGs [KW07]: when two objects are matched, atraceobject is created and referenced to the two objects. The trace objects are
stored in a dictionarytraceDictfor later use.
The inner synchronizer may at times refer to some variables that are not
de-clared in thefor statement, in such cases we resynchronize all matched entries
whenever the outer variables change. For example, the following synchronizer
maintains references between two dictionaries usingnullableRefwhich we have
created:
nullableRefshattri(srcDict,tgtDict){
for [srcObj] in [srcDict]{
{ var tgtRef;
tgtRef = srcObj.attr;
nullableRef(tgtRef, tgtDict);} | srcObj == null
}}
Similarly, the following synchronizer maintains containment references between
two dictionaries usingcontainmentRefwhich we have created:
containmentRefshattri(srcDict,tgtDict){
{containmentRefhattr=attri(srcObj, tgtDict)} }
Now we have seen all language constructs in Beanbag. As an example, let
us construct the findBy synchronizer we have seen in the EJB example.2 The
synchronizer ensures the object to whichdmapskhave anattrattribute equal to
v, and whenvchanges, the synchronizer changekto locate another object whose
attr attribute is equal to the changed v. To achieve this, we first map d to a
dictionary d0 containing only the attrattribute, and then use !d0.!k = v to
find a key mapped to the updatedvind0.
findByhattri(d, v, k) { var d0;
for [a, b] in [d, d0]
{b = a.attr | {a=null;b = null;}} !d0.!k = v;
}
3.4 Formalization
So far our discussion on synchronizers is informal. To precisely characterize the behavior of synchronizers, we need more formal definitions. In this subsection we give the formal definitions of synchronizers and the three properties.
Before turning to synchronizers, we need to first define updates. An update
u defined on some data set Dis an idempotent function u ∈ D → D, that is,
u◦u=u. The idempotent property allows us to apply an update twice and get the
same result.
After we express updates as functions, we can represent the merging of updates as function compositions. However, we would expect the composite functions still
to be updates. To ensure this, we introduce a concept update set. An update setU
defined on a data setDis a set of updates closed on composition, that is,∀u1, u2 ∈
U :u1◦u2 ∈U. To be simple, we assume each data typeDhas a corresponding
update set, denoted byUD andvoid∈UD.
The conflict and preservation of updates can be tested using function
composi-tions. Two updatesu1, u2conflict iffu1◦u2 6=u2◦u1. An updateu1is preserved
inu2iffu1◦u2=u2.
Now we proceed to define synchronizers. A synchronizer ssynchronizingn
variables on data setDconsists of four components:
• a consistency relations.R⊆Dn,
• a state sets.Θ,
• a partial function for synchronizations.synchronize ∈UDn ×s.Θ→ UDn ×
s.Θ,
• and a partial function for initializations.initialize∈Un
D×Dn→UDn×s.Θ
2Because this implementation is not efficient on memory usage, in our compiler we use a more
Given the definition of synchronizer, we can precisely define the properties to characterize the synchronization behavior. Suppose at an arbitrary point of time,
the current state of the synchronizer isθand the current values of the variables are
hv1, . . . , vni. The three properties are defined as follows. Property 1 (Stability)
s.synchronize(void. . .void, θ) =hvoid. . .void, θi
Property 2 (Preservation)
s.synchronize(u1. . . un, θ) =hu′1. . . u′n, θ′i=⇒ ∀i∈ {1. . . n}: ui◦u′i=u′i
s.initialize(u1. . . un, d1. . . dn) =hu′1. . . u′n, θ′′i=⇒ ∀i∈ {1. . . n}: ui◦u′i=u′i
Property 3 (Consistency)
s.synchronize(u1. . . un, θ) =hu′1. . . u′n, θ′i=⇒ hu′
1(v1), u′2(v2). . . u′n(vn)i ∈s.R
s.initialize(u1. . . un, d1. . . dn) =hu′1. . . u′n, θ′′i=⇒ hu′
1(d1), u′2(d2). . . u′n(dn)i ∈s.R
These properties form a starting point of reasoning the behavior of synchroniz-ers and a specification for implementing the synchronizsynchroniz-ers. All our experiments show that Beanbag satisfies these three properties. However, to formally prove the three properties we need formal semantics of all synchronizers, which is beyond the scope of this paper.
4
Implementation and Performance Evaluation
We have implemented a compiler for Beanbag. After compilation, the language will be translated to a Java program. There are two ways for users to use the Java program: 1) they can run it in command line and interact with the synchronizer using the syntax in Figure 3 and Figure 4, or 2) they can integrate this program into their Java project and interact with the synchronizer through Java method calls.
Our implementation uses incremental propagation to ensure a short synchro-nization time. We mainly apply the incremental techniques in two places. One is in conjunction, where we invoke a synchronizer only when a related variable is
updated. The other one is in theforconstruct, where we synchronize entries only
when they are updated by users.
To test how our incremental strategies work in practice, we experiment with the EJB program in Section 2. We also implement a similar program in QVT relations [Obj08] for comparison. This program captures the inter-relations between the two diagrams. QVT relations is an state-based incremental synchronization language and is also the standard of model transformation. The compiler of QVT relations that we use is medini QVT v1.4.0 [ikv], and our experiments are carried out on a laptop with 2 GHz Intel(R) Core(TM) Duo processor and 2 GB RAM.
Figure 5: Synchronization time
number of EJBs and modules, where every 10 EJBs belong to a module and the attributes are randomly assigned. Then we synchronize to get a consistent set of entity beans.
We carry three sets of experiments, each consisting of experiments on different number of EJBs. In the first set of experiment we randomly choose five entity beans and change their names. In the second set we delete five entity beans. In the
third set we insert five entity beans3.
In all experiments the two synchronization programs produce correct results and the time taken to synchronize is shown in Figure 5. Some sets of experiments take quite close time and their lines overlap in the figure. To be fair, we exclude the time during which medini QVT loads and saves XMI files, and only use the in-memory evaluation time reported by medini QVT.
The modification and deletion in Beanbag takes very short time and remains almost constant when the data size increases. The insertion has a liner increase with the size of data . The reason is that we need to compare the name of the inserted entity bean with the names of all modules to find out which module the inserted entity bean belongs to. On the other hand, the time of medini QVT is much longer than Beanbag and is mainly related to the number of EJBs. This is probably because QVT relations works in a state-based way. When synchronizing, medini QVT has to re-check whether all applied rules are still valid and the number
of rules is related to the number ofEJBobjects.
In summary, the experiments show that the incremental strategy in Beanbag can ensure efficient synchronization over large models. The synchronization time is much shorter than a state-based incremental synchronization tool and should be satisfactory for practical use.
3In fact, we have carried the fourth set of experiments: inserting five new EJBs. However, medini
D e p l o y m e n t M o d e l D e p l o y m e n t
V i e w
r e f r e s h
u p d a t e
P e r s i s t e n t M o d e l P e r s i s t e n t
V i e w
r e f r e s h u p d a t e
U p d a t e L i s t e n e r
B e a n b a g S y n c h r o n i z e r
M o d e l U p d a t e r [ U p d a t e s ]
[ s y n c h r o n i z e d u p d a t e s ]
a p p l y
a p p l y
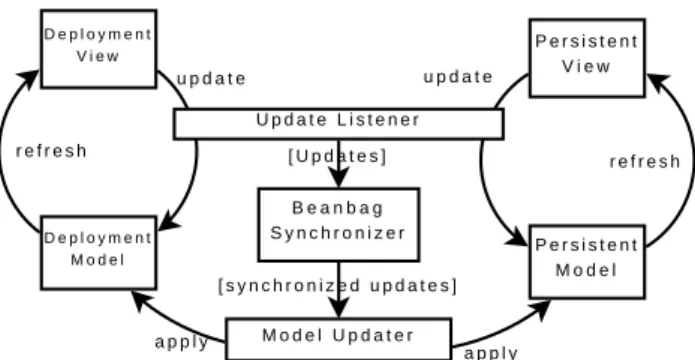
Figure 6: The architecture of the EJB tool
5
Applications
In software engineering, there exist many applications that Beanbag can be applied to. For example, synchronizing multi-views in visual language editors [GHZL06], integration of heterogeneous tools [Tra05], synchronizing software architecture and runtime system [HMY06], and etc. We have successfully applied Beanbag to several case studies. In this section we describe two of them.
EJB Modeling Tool In the first case study we investigate the practicability of Beanbag by constructing a fully functional EJB modeling tool described in Sec-tion 1, and Figure 1 is actually a screen snapshot of the tool we have constructed. The main components of the tool are editing components generated by Eclipse Graphical Modeling Framework (GMF) [Ecl08] and a synchronization component generated from the program in Section 2 by Beanbag, and we only write a few hundred lines of Java code to glue them together.
GMF is a framework for generating graphical editors. Given a model defini-tion, a view definition and their mappings, GMF generates a graphical view that reads from and writes to the model. GMF can generate multiple views for one model, but in a quite limited way: the views and the model cannot be structurally different, and multiple views cannot be edited at the same time. As the two views in the EJB modeling tool are structurally different (one hierarchical and one flat), the tool cannot be directly generated by GMF.
Therefore we discard the usual way of generating two views for one model. Instead, we generate two editors, each with an independent model. The two mod-els can be structurally different and their consistency is maintained by a Beanbag synchronizer. On the interface side, the two editors are both integrated into Eclipse and act like one application.
C l a s s
i s _ p e r s i s t e n t : b o o l C l a s s i f i e r
n a m e : S t r i n g
P r i m i t i v e D a t a T y p e s
A s s o c i a t i o n
n a m e : S t r i n g
p a r e n t A t t r i b u t e
i s _ p r i m a r y : b o o l n a m e : S t r i n g
T a b l e
n a m e : S t r i n g
F K e y C o l u m n
t y p e : S t r i n g n a m e : S t r i n g
p k e y t a b l e
e n c l o s i n g T a b l e
r e f e r e n c e
c o l
e n c l o s i n g C l a s s d e s t
s r c t y p e
C l a s s M e t a M o d e l
R D B M S M e t a M o d e l
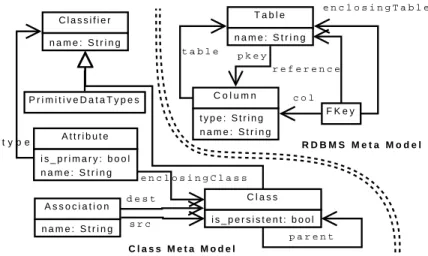
Figure 7: Meta models for Class2RDBMS
One issue of implementing the update listener and the model updater is how to relate the uniquely generated keys (refer to Section 2) to objects in memory. To achieve it, we keep a bijective mapping between the keys and the in-memory addresses of objects. Because the generated keys are just integers, we can easily save the mapping with models using the serialization support of GMF, ensuring that the object addresses are always valid.
This small technique has great value in practice. To identify objects in state-based synchronization, users are often required to designate some key attributes
[Obj08, BFP+08] whose values are unique among all instances. However, based
on our experience, many application data do not have a suitable candidate to be a
key attribute [YKW+08]. On the other hand, as operation-based synchronizers are
tightly integrated into the system, we can directly use the in-memory address and get rid of the key attribute.
Class to RDBMS It should be interesting to see how Beanbag can tackle tra-ditional bidirectional transformation problems. In the second case study, we apply Beanbag to the well-known “Class to RDBMS” transformation [BRST05]. As far as we know, there is yet no proposal claimed for bidirectionalization of the full transformation in the literature.
Figure 7 shows the meta models of the transformation. In the class meta model, a class consists of attributes, where the type of an attribute can either be primitive or another class. There are also associations and parent references between classes. In the RDBMS data model, a table consists of columns and foreign keys, where the type of a column is represented by string.
trans-formation rules so that the correspondence between the two models is clearer. In our rules, each class corresponds to a table. Each attribute corresponds to a column if its type is primitive, and to a foreign key if its type is a class. A parent reference
corresponds to a foreign key if it is notnull. Each association also corresponds to
a foreign key. Note this is only a high level outline of the rules. The actual rules are much more complicated involving attribute mapping and synchronization behavior specification.
We have successfully implemented the above rules in Beanbag and have tested it with 65 different updates. Beanbag works well in all tests. Our implementation can be found in Appendix C.
Our implementation captures not only the inter-relations between the two mod-els but also the intra-relations within the modmod-els, and Beanbag ensures these rela-tions will be composed together and work together well. For example, if a class on the class model is deleted, then not only its corresponding table but also the attributes of the class and their corresponding columns and foreign keys are all deleted. Furthermore, attributes whose type is the deleted class have their types set
tonulland the corresponding column types are set to"". Parent references that
refer to the deleted class are set tonulland the corresponding foreign keys are
deleted.
6
Related Work
6.1 Bidirectional Transformation
The mainstream work of heterogeneous synchronization is bidirectional transfor-mation. Typical work includes lens and similar composition-based approaches
[FGM+07, LHT07], QVT and similar pattern-based approaches [Obj08, KW07],
and etc.
It would be interesting to see whether existing bidirectional transformation lan-guages can support intra-relations without redesign. First, existing bidirectional transformation languages are mainly of state-based semantics, and thus cannot sup-port propagating updates inside a model directly. Although some work on TGGs [GW06] has used operation-based way to increase performance, the semantics is still state-based.
several programs: the local applications and the transformation program. Each time we change one program, we have to make sure all programs consistent. This actually runs back into the situation where heterogeneous synchronization research tries to avoid.
Another idea is to divide the data into smaller pieces which do not have inner constraint, and to write several bidirectional transformation programs to propagate updates among them. This approach works in some cases, but it requires extra work to divide and re-unite the data, which is sometimes not easy. Furthermore, it is also unclear how to invoke the bidirectional transformation programs in a proper order to propagate a specific update.
To sum up, as we could not find a satisfactory solution that can improve ex-isting bidirectional transformation languages to handle intra-relations, we design Beanbag, a new language which handles intra-relations and inter-relations in a uni-fied way.
Many aspects of Beanbag are inspired by bidirectional transformation research.
For example, the composition of synchronizers is inspired by lens [FGM+07], and
the recording of states is inspired by QVT [Obj08] and some previous discussion [Tra08]. On the other hand, we have made a lot of improvements over bidirectional transformation to support intra-relations: our semantics is operation-based, rather than state-based; the conjunction in Beanbag allows free composition of inner rela-tions, and has much more freedom than sequential composition in lens; we design theinitializeprocedure, which replaces thecreatefunction in lens and the object creation semantics in QVT to allow synchronization of no predefined direc-tion.
6.2 Other related work
Some researchers focus on the consistency of multi-views in development envi-ronments, which is a typical application of Beanbag. Liu and et al. [LHG07] uses a spreadsheet-like mechanism to propagate updates among objects. How-ever, the updates can be propagated only in one direction. Some other work
[GHM98, FGH+94] provides general frameworks for view consistency, where
users manually write code for propagating updates in each direction. On the other hand, our approach only requires users to describe the consistency relation in the Beanbag language and they automatically get the ability of propagating updates in all necessary directions.
7
Conclusion and Future Work
In this paper we have proposed Beanbag, a language for operation-based synchro-nization with intra-relations, and have applied it to several applications. Beanbag capture intra-relations and inter-relations in a unified way, and keeps data consis-tent through propagating updates.
Several issues still need attention before Beanbag can be widely used. Here we discuss two issues. The first one is memory consumption. The current implemen-tation buffers a lot of data to achieve incremental synchronization, which cause an overhead on memory consumption. Nevertheless, much of the consumption can probably be reduced by object sharing. We leave this engineering task for future work.
The second issue is conflict reporting. The current synchronizers only report the existence of conflicts. A more preferable way is to report the updated location causing the conflicts so that users know where to solve the conflicts. This can be possibly achieved by extending an update with a source location, which records the original location from which the update is transformed. We plan to further investigate this issue and design an algorithm for keeping the source locations of updates through propagation.
Acknowledgment
The research was supported in part by a grant from Japan Society for the Promotion of Science (JSPS) Grant-in-aid for Scientific Research (A) 19200002, the National Natural Science Foundation of China under Grant No. 60528006 and the National High Technology Research and Development Program of China (863 Program) under Grant No. of 2006AA01Z156.
References
[ACar] Michal Antkiewicz and Krzysztof Czarnecki. Design space of hetero-geneous synchronization. In Proc. 2nd GTTSE, to appear.
[Bea] The Beanbag website. http://code.google.com/p/ synclib/.
[BFP+08] Aaron Bohannon, J. Nathan Foster, Benjamin C. Pierce, Alexandre
Pilkiewicz, and Alan Schmitt. Boomerang: Resourceful lenses for
string data. In Proc. 35th POPL, 2008.
[BRST05] Jean B´ezivin, Bernhard Rumpe, Andy Sch¨urr, and Laurence Tratt. Model transformations in practice workshop. In Satellite Events at
[CS03] Compuware and Sun. XMOF queries, views and transformations on
models using MOF, OCL and patterns. http://www.omg.org/
docs/ad/03-08-07, 2003.
[Ecl08] Eclipse Consortium. The Eclipse Graphical Modeling Framework. http://www.eclipse.org/modeling/gmf/, 2008.
[FGH+94] A. Finkelstein, D. Gabbay, A. Hunter, J. Kramer, and B. Nuseibeh.
Inconsistency handling in multiperspective specifications. IEEE Trans.
Softw. Eng., 20(8):569–578, 1994.
[FGM+07] J. Nathan Foster, Michael B. Greenwald, Jonathan T. Moore,
Ben-jamin C. Pierce, and Alan Schmitt. Combinators for bidirectional tree transformations: A linguistic approach to the view-update problem.
ACM Trans. Program. Lang. Syst., 29(3):17, 2007.
[GHM98] John Grundy, John Hosking, and Warwick B. Mugridge. Inconsis-tency management for multiple-view software development environ-ments. IEEE Trans. Softw. Eng., 24(11):960–981, 1998.
[GHZL06] John C. Grundy, John G. Hosking, Nianping Zhu, and Na Liu. Gener-ating domain-specific visual language editors from high-level tool spec-ifications. In Proc. 21st ASE, pages 25–36, 2006.
[GW06] Holger Giese and Robert Wagner. Incremental model synchronization with triple graph grammars. In Proc. 9th MoDELS, pages 543–557, 2006.
[HMY06] Gang Huang, Hong Mei, and Fu-Qing Yang. Runtime recovery and ma-nipulation of software architecture of component-based systems.
Auto-mated Software Eng., 13(2):257–281, 2006.
[ikv] ikv++ technologies. medini QVT homepage. http://projects. ikv.de/qvt.
[KW07] Ekkart Kindler and Robert Wagner. Triple graph grammars: Concepts, extensions, implementations, and application scenarios. Technical Re-port tr-ri-07-284, University of Paderborn, June 2007.
[LHG07] Na Liu, John Hosking, and John Grundy. Maramatatau: Extending a domain specific visual language meta tool with a declarative constraint mechanism. In Proc. VL/HCC, 2007.
[LHT07] Dongxi Liu, Zhenjiang Hu, and Masato Takeichi. Bidirectional inter-pretation of XQuery. In Proc. PEPM, pages 21–30, 2007.
[Obj08] Object Management Group. MOF query / views /
transforma-tions specification 1.0. http://www.omg.org/docs/formal/
[OMG02] OMG. MetaObject Facility specification. http://www.omg.org/ docs/formal/02-04-03.pdf, 2002.
[PSG03] Benjamin C. Pierce, Alan Schmitt, and Michael B. Greenwald. Bring-ing Harmony to optimism: A synchronization framework for heteroge-neous tree-structured data. Technical Report MS-CIS-03-42, University of Pennsylvania, 2003.
[Ste07] Perdita Stevens. Bidirectional model transformations in QVT: Semantic issues and open questions. In Proc. 10th MoDELS, pages 1–15, 2007.
[Tra05] Laurence Tratt. Model transformations and tool integration. Journal of
Software and Systems Modelling, 4(2):112–122, May 2005.
[Tra08] Laurence Tratt. A change propagating model transformation language.
Journal of Object Technology, 7(3):107–126, March 2008.
[Tsa93] Edward Tsang. Foundations of Constraint Satisfaction. Academic Press, 1993.
[XLH+07] Yingfei Xiong, Dongxi Liu, Zhenjiang Hu, Haiyan Zhao, Masato
Takeichi, and Hong Mei. Towards automatic model synchronization from model transformations. In Proc. 22nd ASE, pages 164–173, 2007.
[YKW+08] Yijun Yu, Haruhiko Kaiya, Hironori Washizaki, Yingfei Xiong, and
Appendix
A
Library Relations in Beanbag
findByhattri(d, v, k) { var d0;
for [a, b] in [d, d0]
{b = a.attr | {a=null;b = null;}} !d0.!k = v;
}
findValueByhattri(d, attr, k, v) { findByhattr=attri(d, attr, k); v = !d.k;
}
findByNoChangeDhattri(d, v, k) { var d0;
for [a, b] in [d, d0]
{b = a.attr | {a=null;b = null;}} d0.!k = v;
}
containmentRefhattri(srcObj, tgtDict){ {
var ref;
ref = srcObj.attr; !tgtDict.ref hi null;
}
| srcObj = null }
containmentRefMaintainerhattri(srcDict, tgtDict) {
for [srcObj] in [srcDict]
containmentRefhattr=attri(srcObj, tgtDict) }
nullableRef(objRef, objs) {objs.!objRef hi null | objRef = null}
nullableRefMaintainerhattri(obj, tgtDict) { {
var tgtRef;
tgtRef = obj.attr;
nullableRef(tgtRef, tgtDict); }
| obj == null }
B
The Beanbag Program for the EJB Modeling Tool
include "lib.sync"
var moduleRef, moduleName, module; ejb."Persistent" = true;
entitybean."EJBName" = ejb."Name"; moduleName = entitybean."ModuleName";
module."Description" = entitybean."ModuleDescription"; moduleRef = ejb."Module";
findValueByhattr="Name"i(modules, moduleName, moduleRef, module); }
nonPersistent(ejb, entitybean) { ejb."Persistent" = false; entitybean = null;
}
main(ejbs, modules, entitybeans) {
containmentRefMaintainerhattr="Module"i(ejbs, modules);
for [ejb, entitybean] in hejbs, entitybeansi { persistent(ejb, entitybean, modules) | nonPersistent(ejb, entitybean) | {ejb = null; entitybean = null;} }
}
C
The Beanbag Program for Class2Relation
include "lib.sync"
assocs2attrs(assocs, attrs, orig_attrs) {
for [assoc, attr, orig_attr] in hassocs, attrs, orig_attrsi { {orig_attr = null; assoc = null; attr = null} |
{assoc = null; attr = orig_attr; orig_attr hi null;} |
{
orig_attr = null;
attr."enclosingClass" = assoc."src"; attr."type" = assoc."dest";
attr."name" = assoc."name"; attr."is_primary" = false; }
} }
classes2tables(classes, tables, traces) {
for [hclassid, classi, htableid, tablei, trace]
in hclasses, tables, tracesi { {
table."name" = class."name"; trace."class" = classid; trace."table" = tableid; } |
{ class = null; table = null; trace = null; } }
}
findByNoChangeDhattr=attri(d, v, k) | { v = null; k = null }
}
inTracehattr1, attr2i(v1, v2, trace) { var key;
nullableFindByhattr=attr1i(trace, v1, key); nullableFindByhattr=attr2i(trace, v2, key); }
isPrimitiveType(attr, classifiers) { var attrTypeRef, type;
attrTypeRef = attr."type"; type = classifiers.!attrTypeRef; type."__type" == "primitive";
}
isClassType(attr, classifiers) { var attrTypeRef, type;
attrTypeRef = attr."type"; type = classifiers.!attrTypeRef; type."__type" == "class";
}
attrType2columnType(attrTypeRef, columnType, classifiers) { {
var type, typeName, ref; {
findValueByhattr="name"i
(classifiers, columnType, ref, type) | {ref=null;columnType=null;}
}
ref = attrTypeRef;
type."__type" = "primitive"; } |
{ attrTypeRef = null; columnType = null; } }
filterClassAttrs(attrs, pattrs, classifiers) {
for [attr, pattr] in [attrs, pattrs] {
{pattr = attr; isPrimitiveType(attr, classifiers)} | {pattr = null; isClassType(attr, classifiers)} | {attr = null; pattr = null;}
} }
attrs2columns(attrs, columns, a2cTraces, c2tTraces, classifiers) { var primitiveAttrs;
filterClassAttrs(attrs, primitiveAttrs, classifiers);
for [hattrid, attri, hcolumnid, columni, htraceid, tracei]